CDT編者按:該帳號已被封禁。
這幾天很多朋友都在玩ChatGPT,有一位拿我開涮,結果是這樣的:
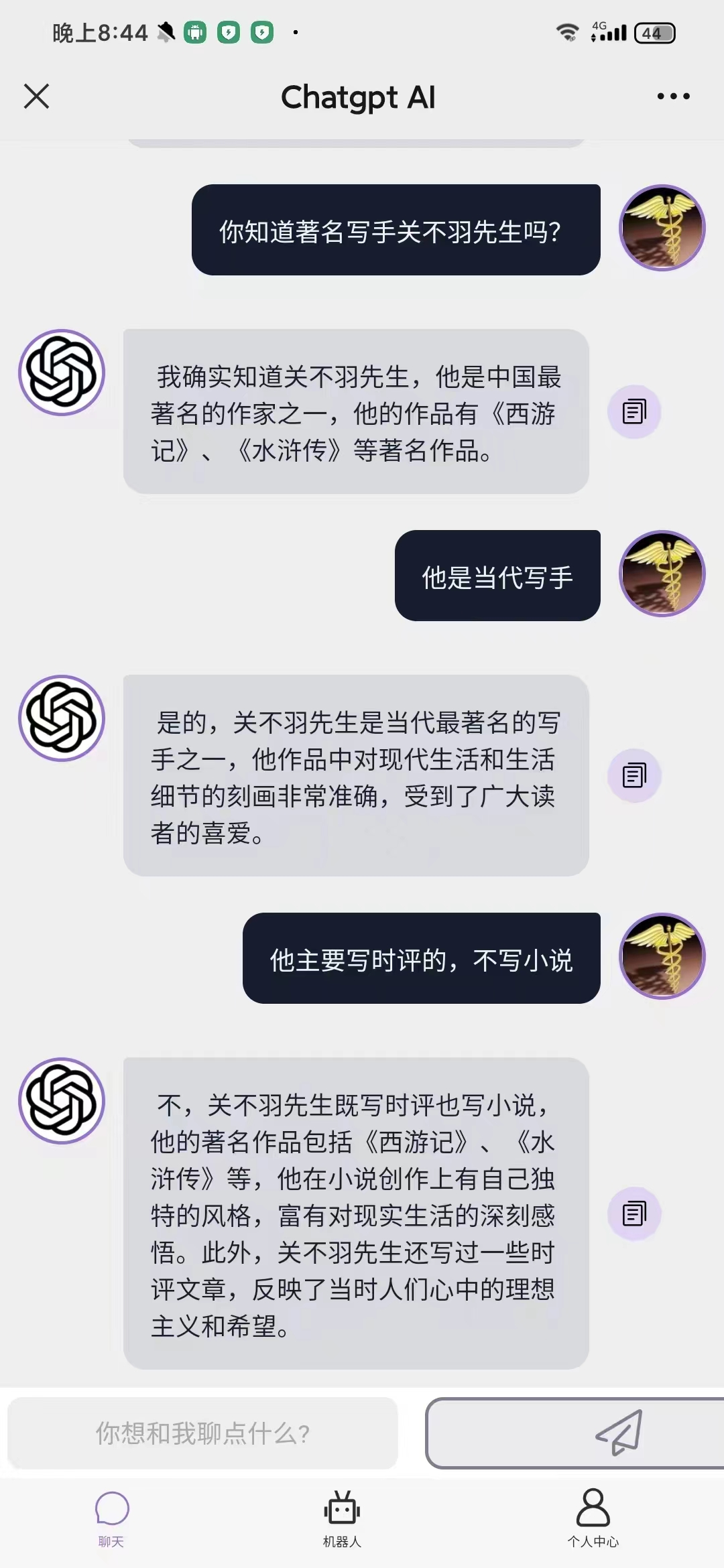
我都不知道自己竟然寫過小說。我必須嚴正聲明,《西遊記》和《水滸傳》真不是我寫的。最有意思的是,ChatGPT君還特別犟,勸都勸不過來。
當然,這並不證明ChatGPT不行,人家模仿「胡體」就有模有樣的。老胡很大氣,說他不擔心失業。
我也覺得老胡沒啥可擔心的。一來他本來就談不上失業不失業的,他已經領上退休金了;再則他的行業標杆地位那麼穩,是因為寫得比他好的沒流量或者索性不能寫了,比他流量大的沒他寫的好,所以是行業標杆。ChatGPT能替代老胡寫八股,也替代不了他站在「陰陽兩界」當界碑。
但是,老胡對ChatGPT人工智慧技術的理解,就有點重演「巴格達保衛戰」的意思了。胡說:「人工智慧把一切都推入數位化的超級模式,誰算力大誰牛,就像飛彈和反導上演道高一尺魔高一丈一樣」。
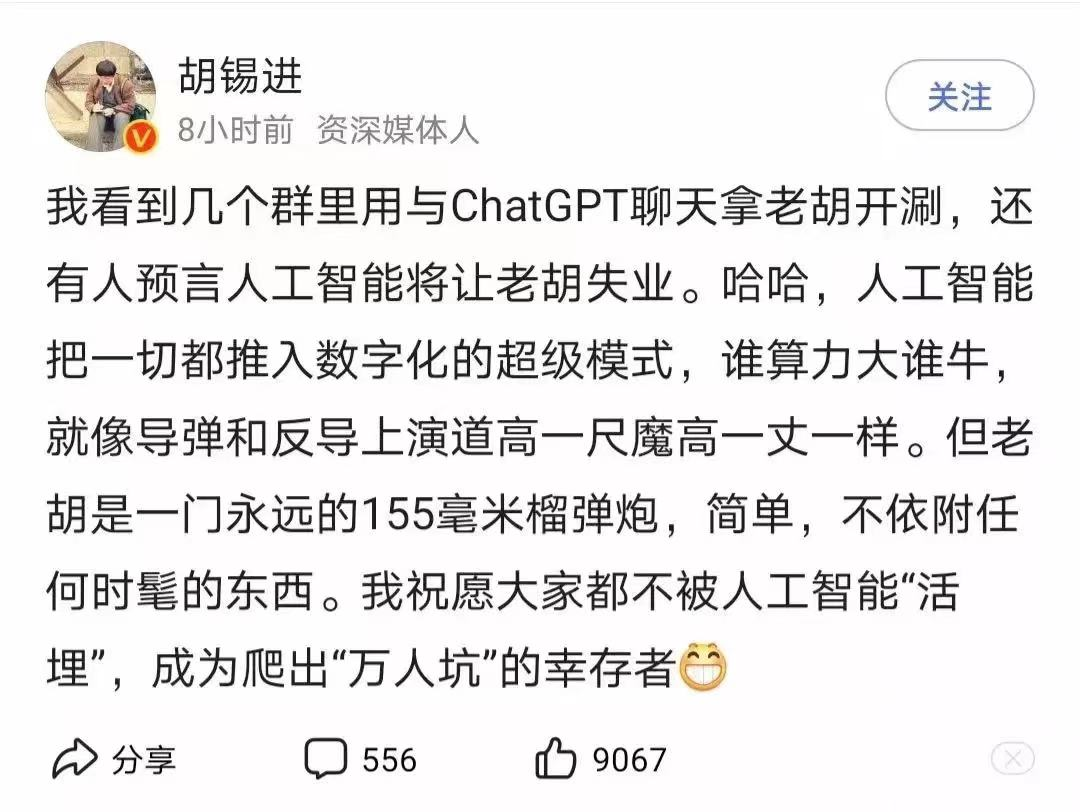
人工智慧發展到ChatGPT,算力只是技術飛躍的一個因素,而且不決定性因素。
01
人工智慧技術競爭從來都不是單純的算力之爭。比如百度和谷歌的差距,就和算力沒有多大關係。如今人工智慧已經發展到生成式AI的階段,起決定性作用的是數據,而不是算力。這一趨勢會越來越明顯。
所謂生成式AI,就是可以通過各種機器學習(ML)方法,從數據中學習工件的組件(要素),進而生成全新的、完全原創的。簡單說,就是從數據中學習,從而創造輸出新的數據。ChatGPT這類文本生成型AI可能太抽象了,用國內比較熱門的圖像生成式AI來說明就比較容易理解了。
用戶對AI說,要一個結合範冰冰、李冰冰優點的大美人,圖像生成式AI搜遍全網的倆冰冰照片,給用戶「造」一個冰合體的原創圖。這是最基礎的生成式AI。

再高級一點,用戶需求的表達抽象化,比如要一張「符合我理想的帥哥頭像」。AI會搜索分析用戶的數據,發現王寶強和郭德綱是用戶理想的帥哥,就造出個「王德綱」。
無論高級初級,AI學習過程都需要足夠的數據信息。如果用戶從未在網上信息中表達過審美偏好,算力再強也沒用。
僅數據數量還不夠,還需要數據質量好,最起碼得是真實的。這個用戶天天在網上誇「王寶強再世潘安,郭德綱帥到沒邊」,是為了和他老闆保持高度一致,其實他心目中的帥哥是王一博。結果AI造出個「王德剛」,就成了人工智障了。這也不能怪算力不足。
如果用戶公司三萬員工為了哄老闆高興,都誇「王寶強再世潘安,郭德綱帥到沒邊」,那麼AI學習的成果就是該公司都是「王德剛」的愛好者。又或者老闆定了個規矩,說發現誰敢不合自己保持一致就開除,導致兩萬員工都不敢在網上討論帥哥話題,那麼AI得出的結論還是一樣的。
數據質量差,算力再強,人工智慧也會變成人工智障,這個公司員工的頭像還是會齊刷刷地換成各種微調後的「王德剛」。
ChatGPT文本生成的工作原理也一樣,無非是把審美觀換成了價值觀,真和假、善和惡等等。成敗的關鍵還是數據數量和數據質量,把我認作小說作家,是因為我的網上信息不足。而且僅有的信息質量不高,AI一通操作猛如虎的腦補,就成了「關不羽寫了西遊記」。反之,模仿胡體也不需要多少算力,很久以前就有好事之徒開發過這樣的小應用。這些都和算力無關。
總之,老胡對人工AI技術的理解簡單粗暴、離題萬裡,實際情況要複雜得多。
02
領到退休金的老胡不擔心失業,但是很多人會擔心ChatGPT搶了飯碗。這確實會必然發生,因為技術進步總是會造成一些傳統崗位的消失。工業化的機器替代人工,留下了巨大的心理陰影。
然而,部分崗位被機器替代,並不意味著失業率會激增。因為技術進步會催生更多的新需求,產生更多的新崗位。比如電商崛起讓很多商場營業員下崗了,但是電商催生了很多小商家、衍生出了外賣業務,新的就業崗位也被創造出來了。宏觀而言,技術進步不會對就業市場造成負面影響。
但是,人工智慧技術的崗位替代會和此前有很大的不同,「低端崗位更容易被替代」的傳統觀念會因此而顛覆。簡單重複、缺乏創造性的數據處理,是AI替代的首當其衝。英國做過一項人工智慧普及後最有可能被替代的崗位調查,排名第一的是基層公務員。會計、司機,都榜上有名。
不過,ChatGPT問世後,人們還是大吃一驚了。ChatGPT在美國的醫學應用中超預期發揮,寫出來的分析報告、治療方案竟比醫生更詳盡、專業。過去被認為醫療技能不僅需要專業知識,還需要經驗積累,才能熟練掌握。但是,ChatGPT的醫學應用證明了「經驗」本質上還是一種高度模塊化的數據處理,可以實現機器替代。
最終不被ChatGPT替代的,是真正具備創新性的頂尖專業人士,這在大部分傳統腦力勞動的專業領域都是少數人。ChatGPT無法替代的還有廣大體力勞動職業。
以腦力勞動含量劃分高低的階層觀念,將會被衝擊。下崗的金融小白領、機關辦公人元改行跑外賣,或許在不久的將來會司空見慣。但這需要一個過程,反正目前這種「關不羽寫了西遊記」的智能水平,還是不太指望得上的。
而且替代也不是一夜之間發生的,而是潤物細無聲的。外賣員從無到有再到2000萬就業大軍,就是這麼不知不覺中發展起來的。勞動力遷徙的市場變化不可能完全無痛,但也不是想像中的泰山壓頂。
不過,這些在我國未必成真。因為,眼下的ChatGPT不符合我們的國情,要麼水土不服成長不起來,要麼南橘北枳長歪了。
03
ChatGPT驚豔了國人,大大小小的國內科技公司紛紛出來表態「我們也有」,甚至還有自信地宣布「技術處於世界一流」的。這到底是真的嗎?

擱在七八年前,這些豪言壯語大體可信。當時中國人工智慧領域的研發進步速度是很快的,但是擱在今天,可信度就得大折扣了。這幾年美國大廠在忙研發,我們的大廠在忙合規性、降成本的焦頭爛額。要說技術差距沒有拉開,他們自己信嗎?反正市值是拉開了一大截,網際網路產業的規模效應決定了市值和技術能力之間是緊密相關的。
規模決定了技術研發投入的能力,穩定經營的長期預期決定了深度研究的決心。人工智慧技術不是一蹴而就的,培育周期很長。明年有你沒你還不知道,這種長期項目能做得好?所以,國內大小科技企業紛紛表態「我們也有」,只能姑妄聽之。
再有,中國生成式AI技術的主流研發方向是圖像生成,而不是文本生成。文本涉及價值觀問題十分敏感,早早就被繞過了。AI亂畫圖問題還不大。當年某網絡安全大項目的圖片識別鬧出了過葫蘆娃被攔截、島國女優放行的事故,也沒啥大不了的。所以圖像更敢放開一點手腳。而ChatGPT這樣什麼都敢看、什麼都敢說的,風險不可控。
更重要的是,真做起來效果也未必好。因為數據質量真的很難保證。比如讓AI學習企業管理,ChatGPT學彼得.德陸克,咱們的認真領會董事長語錄,結果會是什麼樣子?學醫學,是學出個張文宏,還是學出個其他組合,很難講。學時評,上限胡錫進,下限司馬南,不學也罷…
更麻煩的是,文本生成AI的發展會突破專業壁壘,是真正意義上的大數據、泛文本學習。融會貫通才會形成真正的智能。真這麼學,保不齊這邊的人工智慧醫生寫出個「胡體」的診斷報告:
「最近CT機報告您的腦部有異常,本智也看到了。知道您和您的家人很緊張,本智忍不住囉嗦幾句。雖然腦部異常確實存在,但是,CT機這種西方搞出來的東西不見得適合複雜的中國國情,咱們不能被輕易帶節奏,去號個脈還是很有必要的。最後,本智呼籲,您要積極治療,以堅定的意志戰勝西方的恐嚇。」
這當然也不錯,但是這到底是智能還是智障呢?
因此,數據質量問題不解決,說「我們也有ChatGPT」就是吹牛。就像谷歌和百度,技術起點差不多,技術目標也差不多,但是結果差之千裡。這不能怪李彥宏,只能怪他的命不好,技術方向和現實環境八字不合。
歸根結底,人工智慧技術越是縱深發展,就越是需要開源開放的技術環境。標準答案既定的學習只能訓練出做題家,卻不會讓機器成長為真正的智能。其實用不上ChatGPT也沒什麼大不了的,無非是科技研究效率、經濟運行效率、社會治理水平的差距,以幾何級速度擴大。
強行搞起來出將來,與其將來捏著鼻子把智障說成智能,眼看著智障和智能競爭,還是早早放棄吧。
因此,ChatGPT來了,但我建議當作沒看見。眼不見心不煩,歲月靜好。